强化学习简介¶
在本章,我们将对 深度强化学习 一节中所涉及的强化学习算法进行入门介绍。我们所熟知的有监督学习是在带标签的已知训练数据上进行学习,得到一个从数据特征到标签的映射(预测模型),进而预测新的数据实例所具有的标签。而强化学习中则出现了两个新的概念,“智能体”和“环境”。在强化学习中,智能体通过与环境的交互来学习策略,从而最大化自己在环境中所获得的奖励。例如,在下棋的过程中,你(智能体)可以通过与棋盘及对手(环境)进行交互来学习下棋的策略,从而最大化自己在下棋过程中获得的奖励(赢棋的次数)。
如果说有监督学习关注的是“预测”,是与统计理论关联密切的学习类型的话,那么强化学习关注的则是“决策”,与计算机算法(尤其是动态规划和搜索)有着深入关联。笔者认为强化学习的原理入门相较于有监督学习而言具有更高的门槛,尤其是给习惯于确定性算法的程序员突然呈现一堆抽象概念的数值迭代关系,在大多数时候只能是囫囵吞枣。于是笔者希望通过一些较为具体的算例,以尽可能朴素的表达,为具有一定算法基础的读者说明强化学习的基本思想。
从动态规划说起¶
如果你曾经参加过NOIP或ACM之类的算法竞赛,或者为互联网公司的机考做过准备(如LeetCode),想必对动态规划(Dynamic Programming,简称DP)不会太陌生。动态规划的基本思想是将待求解的问题分解成若干个结构相同的子问题,并保存已解决的子问题的答案,在需要的时候直接利用 1 。使用动态规划求解的问题需要满足两个性质:
最优子结构:一个最优策略的子策略也是最优的。
无后效性:过去的步骤只能通过当前的状态影响未来的发展,当前状态是历史的总结。
我们回顾动态规划的经典入门题目 “数字三角形” :
数字三角形问题
给定一个形如下图的 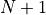 层数字三角形及三角形每个坐标下的数字
层数字三角形及三角形每个坐标下的数字  ,智能体在三角形的顶端,每次可以选择向下(
,智能体在三角形的顶端,每次可以选择向下(  )或者向右(
)或者向右(  )到达三角形的下一层,请输出一个动作序列,使得智能体经过的路径上的数字之和最大。
)到达三角形的下一层,请输出一个动作序列,使得智能体经过的路径上的数字之和最大。
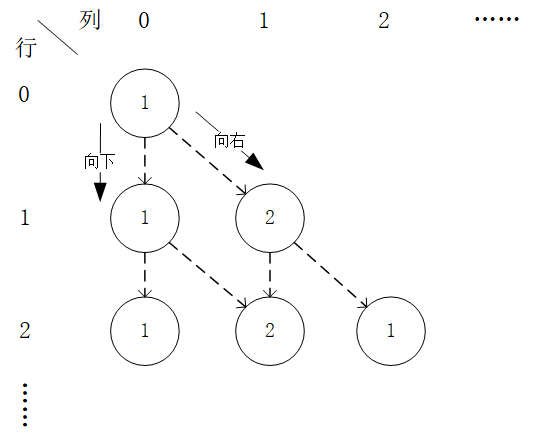
数字三角形示例。此示例中最优动作序列为“向右-向下”,最优路径为“(0, 0) - (1, 1) - (2, 1)”,最大数字和为 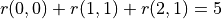 。¶
。¶
我们先不考虑如何寻找最优动作序列的问题,而假设我们已知智能体在每个坐标(i, j)处会选择的动作 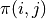 (例如
(例如 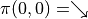 代表智能体在(0, 0)处会选择向右的动作),我们只是单纯计算智能体会经过的路径的数字之和。我们从下而上地考虑问题,设
代表智能体在(0, 0)处会选择向右的动作),我们只是单纯计算智能体会经过的路径的数字之和。我们从下而上地考虑问题,设 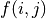 为智能体在坐标(i, j)处的“现在及未来将会获得的数字之和”,则可以递推地写出以下等式:
为智能体在坐标(i, j)处的“现在及未来将会获得的数字之和”,则可以递推地写出以下等式:
(1)¶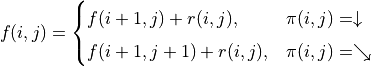
上式的另一个等价写法如下:
(2)¶![f(i, j) = [p_1 f(i+1, j) + p_2 f(i+1, j+1)] + r(i, j)](../../_images/math/9e4c2f6d79f84bc4cefd367c1242fe615dc4a515.png)
其中
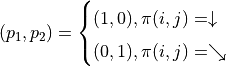
有了上面的铺垫之后,我们要解决的问题就变为了:通过调整智能体在每个坐标(i, j)会选择的动作 的组合,使得 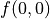 的值最大。为了解决这个问题,最粗暴的方法是遍历所有 的组合,例如在示例图中,我们需要决策
的值最大。为了解决这个问题,最粗暴的方法是遍历所有 的组合,例如在示例图中,我们需要决策 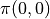 、
、 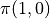 、
、 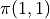 的值,一共有
的值,一共有 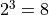 种组合,我们只需要将8种组合逐个代入并计算 ,输出最大值及其对应组合即可。
种组合,我们只需要将8种组合逐个代入并计算 ,输出最大值及其对应组合即可。
不过,这样显然效率太低了。于是我们考虑直接计算 (2) 式关于所有动作 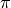 组合的最大值
组合的最大值 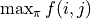 。在 (2) 式中, 与任何动作 都无关,所以我们只需考虑
。在 (2) 式中, 与任何动作 都无关,所以我们只需考虑 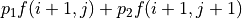 这个表达式的最大值。于是,我们分别计算
这个表达式的最大值。于是,我们分别计算 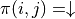 和
和 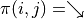 时该表达式关于任何动作 的最大值,并取两个最大值中的较大者,如下所示:
时该表达式关于任何动作 的最大值,并取两个最大值中的较大者,如下所示:
![\max_\pi f(i, j) &= \max_\pi [p_1 f(i+1, j) + p_2 f(i+1, j+1)] + r(i, j) \\
&= \max [\underbrace{\max_\pi(1 f(i+1, j) + 0 f(i+1, j+1))}_{\pi(i, j) = \downarrow}, \underbrace{\max_\pi(0 f(i+1, j) + 1 f(i+1, j+1))}_{\pi(i, j) = \searrow}] + r(i, j) \\
&= \max [\underbrace{\max_\pi f(i+1, j)}_{\pi(i, j) = \downarrow}, \underbrace{\max_\pi f(i+1, j+1)}_{\pi(i, j) = \searrow}] + r(i, j)](../../_images/math/216c0118c700082f830d23cfcb90c8fc07dd2bf7.png)
令 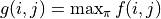 ,上式可写为
,上式可写为 ![g(i, j) = \max[g(i+1, j), g(i+1, j+1)] + r(i, j)](../../_images/math/81d9d1e63f1a6c10ba011bccc2a5b445aecdbc19.png) ,这即是动态规划中常见的“状态转移方程”。通过状态转移方程和边界值
,这即是动态规划中常见的“状态转移方程”。通过状态转移方程和边界值  ,我们即可自下而上高效地迭代计算出
,我们即可自下而上高效地迭代计算出  。
。
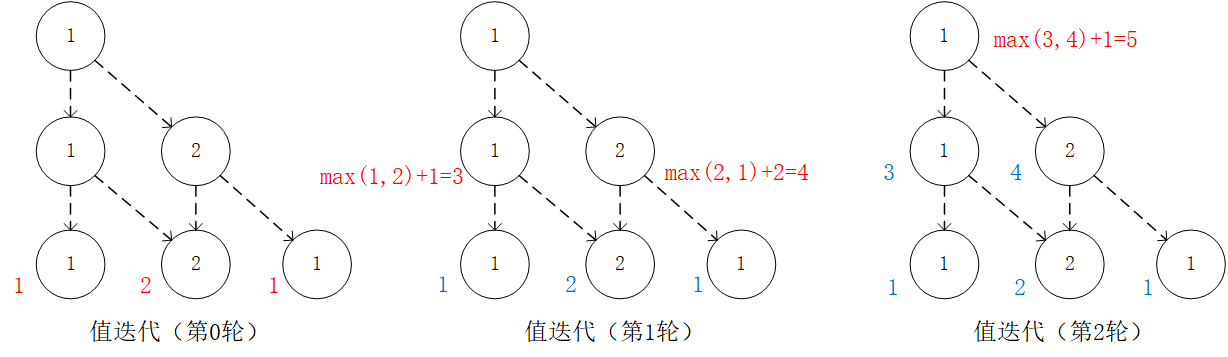
通过对 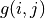 的值进行三轮迭代计算
的值进行三轮迭代计算 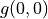 。在每一轮迭代中,对于坐标(i, j),分别取得当 和 时的“未来将会获得的数字之和的最大值”(即
。在每一轮迭代中,对于坐标(i, j),分别取得当 和 时的“未来将会获得的数字之和的最大值”(即 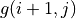 和
和 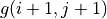 ),取两者中的较大者,并加上当前坐标的数字 。¶
),取两者中的较大者,并加上当前坐标的数字 。¶
加入随机性和概率的动态规划¶
在实际生活中,我们做出的决策往往并非完全确定地指向某个结果,而是同时受到环境因素的影响。例如选择磨练棋艺固然能让一个人赢棋的概率变高,但也并非指向百战百胜。正所谓“既要靠个人的奋斗,也要考虑到历史的行程”。对应于我们在前节讨论的数字三角形问题,我们考虑以下变种:
数字三角形问题(变式1)
智能体初始在三角形的顶端,每次可以选择向下( )或者向右( )的动作。不过环境会对处于任意坐标(i, j)的智能体的动作产生“干扰”,导致以下的结果:
如果选择向下(
),则该智能体最终到达正下方坐标(i+1, j)的概率为  ,到达右下方坐标(i+1, j+1)的概率为
,到达右下方坐标(i+1, j+1)的概率为  。
。如果选择向右(
),则该智能体最终到达正下方坐标(i+1, j)的概率为 ,到达右下方坐标(i+1, j+1)的概率为 。
请给出智能体在每个坐标所应该选择的动作 ,使得智能体经过的路径上的数字之和的期望(Expectation) 2 最大。
此时,如果你想直接写出问题的状态转移方程,恐怕就不那么容易了(动作选择和转移结果不是一一对应的!)。但如果类比前节 (2) 式描述问题的框架,我们会发现问题容易了一些。在这个问题中,我们沿用符号 来表示智能体在坐标(i, j)处的“现在及未来将会获得的数字之和的期望”,则有“当前(i, j)坐标的期望 = ‘选择动作 后可获得的数字之和’的期望 + 当前坐标的数字”,如下式
(3)¶
其中
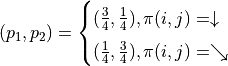
类比前节的推导过程,令 ,我们可以得到
(4)¶![g(i, j) = \max[\underbrace{\frac{3}{4} g(i+1, j) + \frac{1}{4} g(i+1, j+1)}_{\pi(i, j) = \downarrow}, \underbrace{\frac{1}{4} g(i+1, j) + \frac{3}{4} g(i+1, j+1)}_{\pi(i, j) = \searrow}] + r(i, j)](../../_images/math/acde73d4b06bbf3cff2ce244f3e3221b08c0ae47.png)
然后我们即可使用这一递推式由下到上计算 。
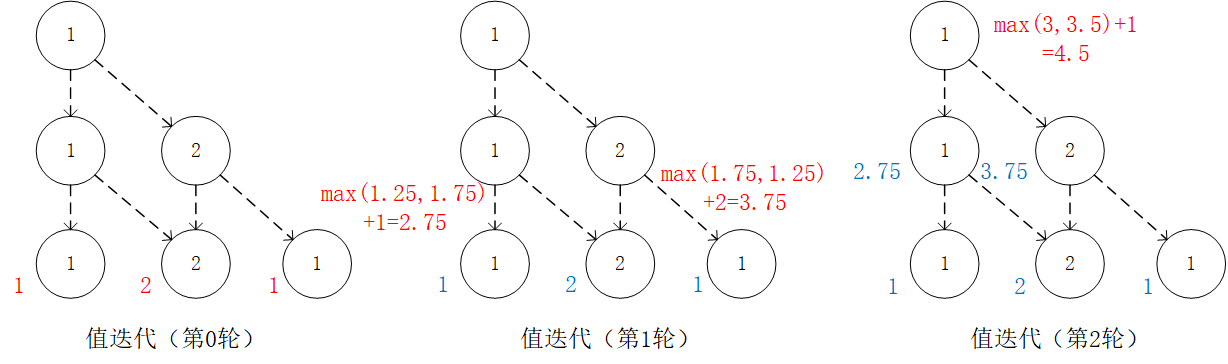
通过对 的值进行三轮迭代计算 。在每一轮迭代中,对于坐标(i, j),分别计算当 和 时的“未来将会获得的数字之和的期望的最大值”(即 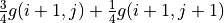 和
和 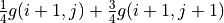 ),取两者中的较大者,并加上当前坐标的数字 。¶
),取两者中的较大者,并加上当前坐标的数字 。¶
我们也可以从智能体在每个坐标(i, j)所做的动作 出发来观察 (4) 式。在每一轮迭代中,先分别计算两种动作带来的未来收益期望(策略评估),然后取收益较大的动作作为 的取值(策略改进),最后根据动作更新 。
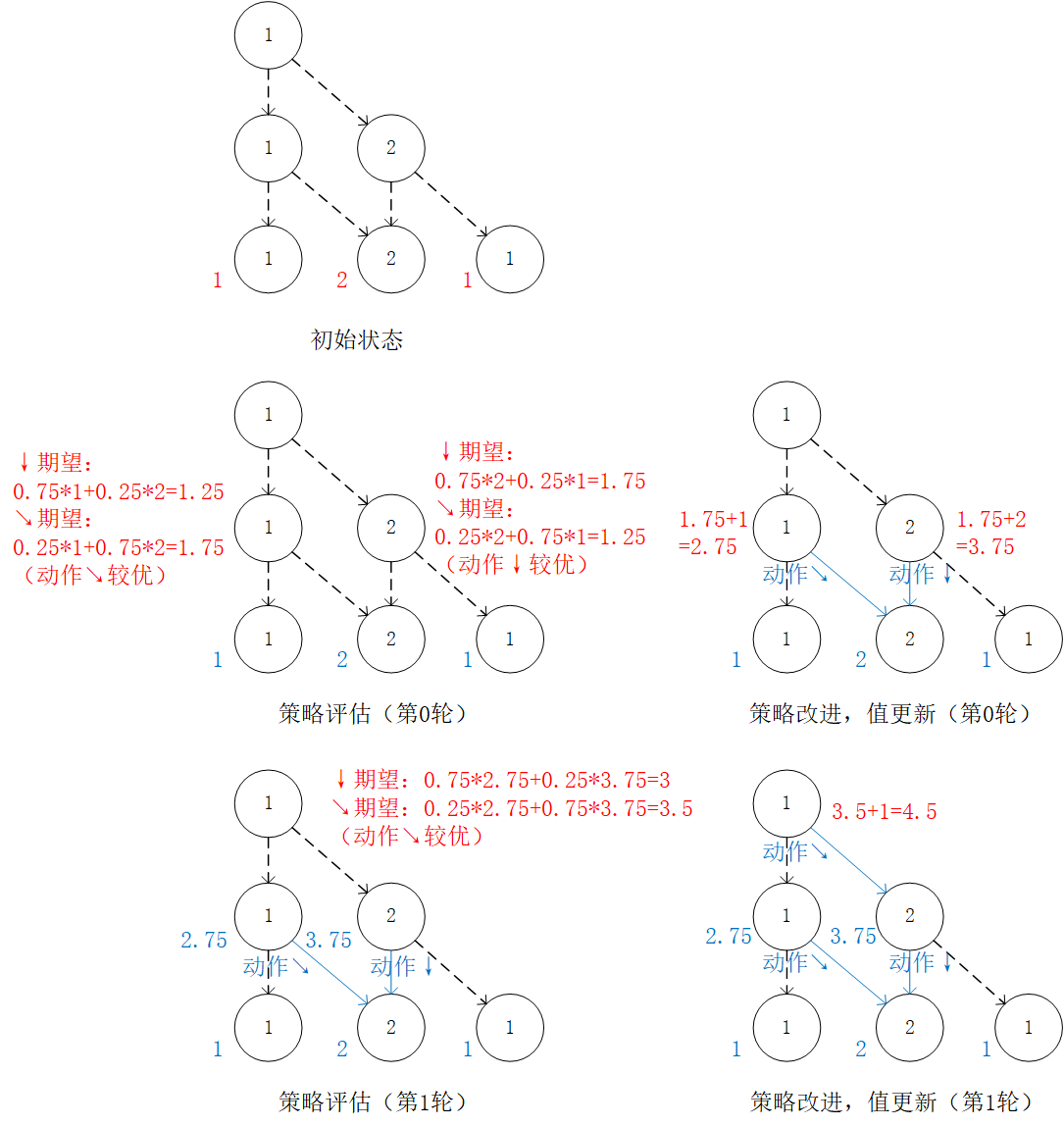
策略评估-策略改进框架:通过对 的值进行迭代来计算 。在每一轮迭代中,对于坐标(i, j),分别计算当 和 时的“未来将会获得的数字之和的期望”(策略评估),取较大者对应的动作作为 的取值(策略改进)。然后根据本轮迭代确定的 的值更新 。¶
我们可以将算法流程概括如下:
初始化环境
for i = N-1 downto 0 do
(策略评估)计算第i层中每个坐标(i, j)选择
和 的未来期望 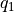 和
和 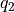
(策略改进)对第i层中每个坐标(i, j),取未来期望较大的动作作为
的取值(值更新)根据本轮迭代确定的
的值更新 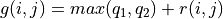
环境信息无法直接获得的情况¶
让我们更现实一点:在很多现实情况中,我们甚至连环境影响所涉及的具体概率值都不知道,而只能通过在环境中不断试验去探索总结。例如,当学习了一种新的围棋定式时候,我们并无法直接获得胜率提升的概率,只有与对手使用新定式实战多盘才能知道这个定式是好是坏。对应于数字三角形问题,我们再考虑以下变式:
数字三角形问题(变式2)
智能体初始在三角形的顶端,每次可以选择向下( )或者向右( )的动作。环境会对处于任意坐标(i, j)的智能体的动作产生“干扰”,而且这个干扰的具体概率(即上节中的 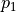 和
和 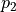 )未知。不过,允许在数字三角形的环境中进行多次试验。当智能体在坐标(i, j)时,可以向数字三角形环境发送动作指令 或 ,数字三角形环境将返回智能体最终所在的坐标(正下方(i+1, j)或右下方(i+1, j+1))。请设计试验方案和流程,确定智能体在每个坐标所应该选择的动作 ,使得智能体经过的路径上的数字之和的期望最大。
)未知。不过,允许在数字三角形的环境中进行多次试验。当智能体在坐标(i, j)时,可以向数字三角形环境发送动作指令 或 ,数字三角形环境将返回智能体最终所在的坐标(正下方(i+1, j)或右下方(i+1, j+1))。请设计试验方案和流程,确定智能体在每个坐标所应该选择的动作 ,使得智能体经过的路径上的数字之和的期望最大。
我们可以通过大量试验来估计动作为 或 时概率 和 的值,不过这在很多现实问题中是困难的。事实上,我们有另一套方法,使得我们不必显式估计环境中的概率参数,也能得到最优的动作策略。
回到前节的“策略评估-策略改进”框架,我们现在遇到的最大困难是无法在“策略评估”中通过前一阶段的 、 和概率参数 、 直接计算每个动作的未来期望 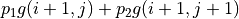 (因为概率参数未知)。不过,期望的妙处在于:就算我们无法直接计算期望,我们也是可以通过大量试验估计出期望的。如果我们用
(因为概率参数未知)。不过,期望的妙处在于:就算我们无法直接计算期望,我们也是可以通过大量试验估计出期望的。如果我们用 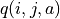 表示智能体在坐标(i, j)选择动作a时的未来期望 3 ,则我们可以观察智能体在(i, j)处选择动作a后的K次试验结果,取这K次结果的平均值作为估计值。例如,当智能体在坐标(0, 1)并选择动作 时,我们进行20次试验,发现15次的结果为1,5次的结果为2,则我们可以估计
表示智能体在坐标(i, j)选择动作a时的未来期望 3 ,则我们可以观察智能体在(i, j)处选择动作a后的K次试验结果,取这K次结果的平均值作为估计值。例如,当智能体在坐标(0, 1)并选择动作 时,我们进行20次试验,发现15次的结果为1,5次的结果为2,则我们可以估计 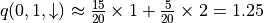 。
。
于是,我们只需将前节“策略评估”中的未来期望计算,更换为使用试验估计  和
和  时的未来期望 ,即可在环境概率参数未知的情况下进行“策略评估”步骤。值得一提的是,由于我们不需要显式计算期望 ,所以我们也无须关心 的值了,前节值更新的步骤也随之省略(事实上,这里 已经取代了前节 的地位)。
时的未来期望 ,即可在环境概率参数未知的情况下进行“策略评估”步骤。值得一提的是,由于我们不需要显式计算期望 ,所以我们也无须关心 的值了,前节值更新的步骤也随之省略(事实上,这里 已经取代了前节 的地位)。
还有一点值得注意的是,由于试验是一个从上而下的步骤,需要算法为整个路径均提供动作,那么对于那些尚未确定动作 的坐标应该如何是好呢?我们可以对这些坐标使用“随机动作”,即50%的概率选择 ,50%的概率选择 ,以在试验过程中对两种动作均进行充分的“探索”。
将前节“策略评估”中的未来期望计算,更换为使用试验估计 和 时的未来期望 。¶
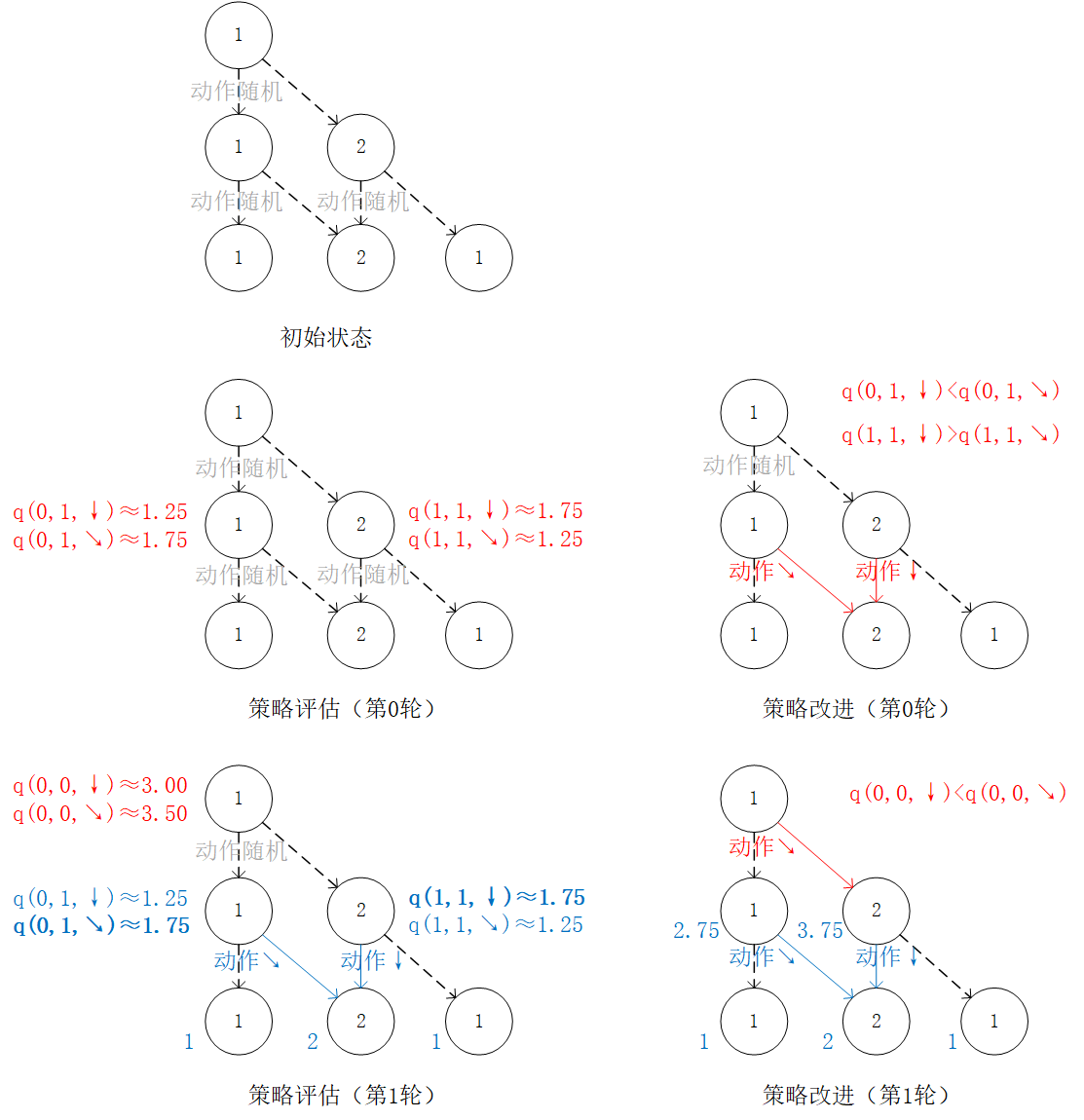
我们可以将算法流程概括如下:
初始化q值
for i = N-1 downto 0 do
(策略评估)试验估计第i层中每个坐标(i, j)选择
和 的未来期望 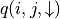 和
和 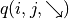
(策略改进)对第i层中每个坐标(i, j),取未来期望较大的动作作为
的取值
从直接算法到迭代算法¶
到目前为止,我们都非常严格地遵循了动态规划中“划分阶段”的思想,即按照问题的时间特征将问题分成若干个阶段并依次求解。对应到数字三角形问题中,即从下到上逐层计算和更新未来期望(或q值),每一轮迭代中更新本层的未来期望(或q值)。在这个过程中,我们很确定,经过N次策略评估和策略改进后,算法将停止,而我们可以获得精确的最大数字和和最优动作。我们将这种算法称为“直接算法”,这也是我们在各种算法竞赛中常见的算法类型。
不过在实际场景中,算法的计算时间往往是有限的,因此我们可能需要算法具有较好的“渐进特性”,即并不要求算法输出精确的理论最优解,只需能够输出近似的较优解,且解的质量随着迭代次数的增加而提升。我们往往称这种算法为“迭代算法”。对于数字三角形问题,我们考虑以下变式:
数字三角形问题(变式3)
智能体初始在三角形的顶端,每次可以选择向下( )或者向右( )的动作。环境会对处于任意坐标(i, j)的智能体的动作产生“干扰”,而且这个干扰的具体概率未知。允许在数字三角形的环境中进行 K 次试验(K可能很小也可能很大)。请设计试验方案和流程,确定智能体在每个坐标所应该选择的动作 ,使得智能体经过的路径上的数字之和的期望尽可能大。
为了解决这个问题,我们不妨从更高的层次来审视我们目前的算法做了什么。其实算法的主体是交替进行“策略评估”和“策略改进”两个步骤。其中,
“策略评估”根据智能体在坐标(i, j)的动作
,评估在这套动作组合下,智能体在坐标(i, j)选择动作a的未来期望 。“策略改进”根据上一步计算出的
,选择未来期望最大的动作来更新动作 。
事实上,这一“策略评估”和“策略改进”的交替步骤并不一定需要按照层的顺序自下而上进行。我们只要确保算法能根据有限的试验结果“尽量”反复进行策略评估和策略改进,就能让算法输出的结果“渐进”地越变越好。于是,我们考虑以下算法流程
初始化
和 repeat
固定智能体的动作
的取值,进行k次试验(试验时加入一些随机扰动,使得能“探索”更多动作组合,上节也有类似操作)。(策略评估)根据当前k次试验的结果,调整智能体的未来期望
的取值,使得 的取值“尽量”能够真实反映智能体在当前动作 下的未来期望(上节是精确调整 4 至等于未来期望)。(策略改进)根据当前
的值,选择未来期望较大的动作作为 的取值。
until 所有坐标的q值都不再变化,或总试验次数大于K
为了理解这个算法,我们不妨考虑一种极端情况:假设每轮迭代的试验次数k的值足够大,则策略评估步骤中可以将 精确调整为完全等于智能体在当前动作 下的未来期望,事实上就变成了上节算法的“粗放版”(上节的算法每次只更新一层的 值为精确的未来期望,这里每次都更新了所有的 值。在结果上没有差别,只是多了一些冗余计算)。
上面的算法只是一个大致的框架介绍。为了具体实现算法,我们接下来需要讨论两个问题:一是如何根据k次试验的结果更新智能体的未来期望 ,二是如何在试验时加入随机的探索机制。
q值的渐进性更新¶
当每轮迭代的试验次数k足够大、覆盖的情形足够广,以至于每个坐标(i, j)和动作a的组合都有足够多的数据的时候,q值的更新很简单:根据试验结果为每个(i, j, a)重新计算一个新的 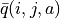 ,并替换原有数值即可。
,并替换原有数值即可。
可是现在,我们一共只有较少的k次试验结果(例如5次或10次)。尽管这k次试验是基于当前最新的动作方案 来实施的,可一是次数太少统计效应不明显,二是原来的q值也不见得那么不靠谱(毕竟每次迭代并不见得会把 更改太多)。于是,相比于根据试验结果直接计算一个新的q值 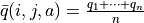 并覆盖原有值(我们在前面的直接算法里一直都是这样做的 5 ):
并覆盖原有值(我们在前面的直接算法里一直都是这样做的 5 ):
(5)¶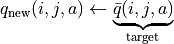
一个更聪明的方法是“渐进”地更新q值。也就是说,我们把旧的q值向当前试验的结果 稍微“牵引”一点,作为新的q值,从而让新的q值更贴近当前试验的结果 ,即
(6)¶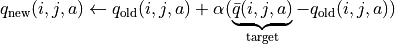
其中参数 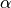 控制牵引的“力度”(牵引力度为1时,就退化为了使用试验结果直接覆盖q值的 (5) 式,不过我们一般会设一个小一点的数字,比如0.1或0.01)。通过这种方式,我们既加入了新的试验所带来的信息,又保留了部分旧的知识。其实很多迭代算法都有类似的特点。
控制牵引的“力度”(牵引力度为1时,就退化为了使用试验结果直接覆盖q值的 (5) 式,不过我们一般会设一个小一点的数字,比如0.1或0.01)。通过这种方式,我们既加入了新的试验所带来的信息,又保留了部分旧的知识。其实很多迭代算法都有类似的特点。
不过, 的值只有当一次试验完全做完的时候才能获得。也就是说,只有走到了数字三角形的最底层,才能知道路径途中的每个坐标到路径最底端的数字之和(从而更新路径途中的所有坐标的q值)。这在有些场景会造成效率的低下,所以我们在实际更新时往往使用另一种方法,使得我们每走一步都可以更新一次q值。具体地说,假设某一次试验中我们在数字三角形的坐标(i, j)处,通过执行动作 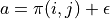 (
( 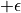 代表加上一些探索扰动)而跳到了坐标(i’,j’)(即“走一步”,可能是(i+1, j),也可能是(i+1, j+1)),然后又在坐标(i’,j’)执行了动作
代表加上一些探索扰动)而跳到了坐标(i’,j’)(即“走一步”,可能是(i+1, j),也可能是(i+1, j+1)),然后又在坐标(i’,j’)执行了动作 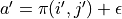 。这时我们可以用
。这时我们可以用 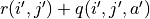 来近似替代之前的 ,如下式所示:
来近似替代之前的 ,如下式所示:
(7)¶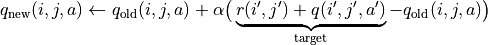
我们甚至可以不需要试验结果中的 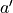 ,而使用在坐标(i’, j’)时两个动作对应的q值的较大者
,而使用在坐标(i’, j’)时两个动作对应的q值的较大者 ![\max[q(i', j', \downarrow), q(i', j', \searrow)]](../../_images/math/c2a42f4c5fdd132bb9e491f72bb751332c448310.png) 来代替
来代替 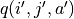 ,如下式:
,如下式:
(8)¶![q_{\text{new}}(i, j, a) \leftarrow q_{\text{old}}(i, j, a) + \alpha\big(\underbrace{r(i', j') + \max[q(i', j', \downarrow), q(i', j', \searrow)]}_{\text{target}} - q_{\text{old}}(i, j, a)\big)](../../_images/math/baf7c525dd74dc28da7bca242c2645153e564685.png)
探索策略¶
对于我们前面介绍的,基于试验的算法而言,由于环境里的概率参数是未知的(类似于将环境看做黑盒),所以我们在试验时一般都需要加入一些随机的“探索策略”,以保证试验的结果能覆盖到比较多的情况。否则的话,由于智能体在每个坐标都具有固定的动作 ,所以试验的结果会受到极大的限制,导致陷入局部最优的情况。考虑最极端的情况,假若我们回到本节之初的原版数字三角形问题(环境确定、已知且不受概率影响),当动作 也固定时,无论进行多少次试验,结果都是完全固定且唯一的,使得我们没有任何改进和优化的空间。
探索的策略有很多种,在此我们介绍一种较为简单的方法:设定一个概率比例  ,以 的概率随机生成动作( 或 ),以
,以 的概率随机生成动作( 或 ),以 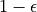 的概率选择动作 。我们可以看到,当
的概率选择动作 。我们可以看到,当 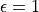 时,相当于完全随机地选取动作。当
时,相当于完全随机地选取动作。当 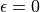 时,则相当于没有加入任何随机扰动,直接选择动作 。一般而言,在迭代初始的时候 的取值较大,以扩大探索的范围。随着迭代次数的增加, 的值逐渐变优, 的取值会逐渐减小。
时,则相当于没有加入任何随机扰动,直接选择动作 。一般而言,在迭代初始的时候 的取值较大,以扩大探索的范围。随着迭代次数的增加, 的值逐渐变优, 的取值会逐渐减小。
大规模问题的求解¶
算法设计有两个永恒的指标:时间和空间。通过将直接算法改造为迭代算法,我们初步解决了算法在时间消耗上的问题。于是我们的下一个挑战就是空间消耗,这主要体现在q值的存储上。在前面的描述中,我们不断迭代更新 的值。这默认了我们在内存中建立了一个 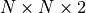 的三维数组,可以记录并不断更新q值。然而,假若N很大,而计算机的内存空间又很有限,那我们该怎么办呢?
的三维数组,可以记录并不断更新q值。然而,假若N很大,而计算机的内存空间又很有限,那我们该怎么办呢?
我们来思考一下,当我们具体实现 时,我们需要其能够实现的功能有二:
q值映射:给定坐标(i, j)和动作a(
或 ),可以输出一个 值。q值更新:给定坐标(i, j)、动作a和目标值target,可以更新q值映射,使得更新后输出的
距离目标值target更近。
事实上,我们有不少近似方法,可以让我们在不使用太多内存的情况下实现一个满足以上两个功能的 。这里介绍一种最流行的方法,即使用深度神经网络近似实现 :
q值映射:将坐标(i, j)输入深度神经网络,网络输出在坐标(i, j)下的所有动作的q值(即
和 )。q值更新:给定坐标(i, j)、动作a和目标值target,将坐标(i, j)输入深度神经网络,网络输出在坐标(i, j)下的所有动作的q值,取其中动作为a的q值为
,并定义损失函数 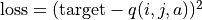 ,使用优化器(例如梯度下降)对该损失函数进行一步优化。此处优化器的步长和上文中的“牵引参数” 作用类似。
,使用优化器(例如梯度下降)对该损失函数进行一步优化。此处优化器的步长和上文中的“牵引参数” 作用类似。
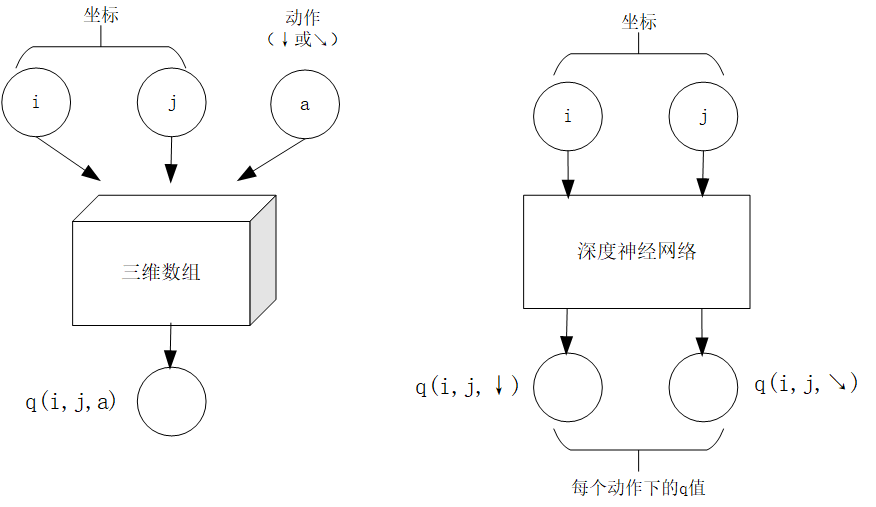
对于数字三角形问题,左图为使用三维数组实现 ,右图为使用深度神经网络近似实现 ¶
总结¶
尽管我们在前文中并未提及“强化学习”一词,但其实我们在对数字三角形问题各种变式的讨论中,已经涉及了很多强化学习的基本概念及算法,在此列举:
在第二节中,我们讨论了基于模型的强化学习(Model-based Reinforcement Learning),包括值迭代(Value Iteration)和策略迭代(Policy Iteration)两种方法。
在第三节中,我们讨论了无模型的强化学习(Model-free Reinforcement Learning)。
在第四节中,我们讨论了蒙特卡罗方法(Monte-Carlo Method)和时间差分法(Temporial-Difference Method),以及SARSA和Q-learning两种学习方法。
在第五节中,我们讨论了使用Q网络(Q-Network)近似实现Q函数来进行深度强化学习(Deep Reinforcement Learning)。
其中部分术语对应关系如下:
数字三角形的坐标(i, j)被称为状态(State),用
 表示。状态的集合用
表示。状态的集合用 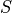 表示。
表示。智能体的两种动作
和 被称为动作(Action),用  表示。动作的集合用
表示。动作的集合用 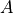 表示。
表示。数字三角形在每个坐标的数字
被称为奖励(Reward),用 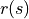 (只与状态有关)或
(只与状态有关)或 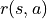 (与状态和动作均有关)表示。奖励的集合用
(与状态和动作均有关)表示。奖励的集合用 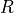 表示。
表示。数字三角形环境中的概率参数
和 被称为状态转移概率(State Transition Probabilities),用一个三参数函数 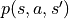 表示,代表在状态s进行动作a到达状态s’的概率。
表示,代表在状态s进行动作a到达状态s’的概率。状态、动作、奖励、状态转移概率,外加一个时间折扣系数
![\gamma \in [0, 1]](../../_images/math/8f5323e15333106b53044416326c30071818c4ab.png) 的五元组构成一个马尔可夫决策过程(Markov Decision Process,简称MDP)。数字三角形问题中
的五元组构成一个马尔可夫决策过程(Markov Decision Process,简称MDP)。数字三角形问题中 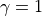 。
。第二节中MDP已知的强化学习称为基于模型的强化学习,第三节MDP的状态转移概率未知的强化学习称为无模型的强化学习。
智能体在每个坐标 (i, j) 处会选择的动作
被称为策略(Policy),用 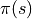 表示。智能体的最优策略用
表示。智能体的最优策略用 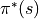 表示。
表示。第二节中,当策略
一定时,智能体在坐标(i, j)处 “现在及未来将会获得的数字之和的期望” 被称为状态-价值函数(State-Value Function),用 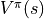 表示。智能体在坐标(i, j)处“未来将会获得的数字之和的期望的最大值” 被称为最优策略下的状态-价值函数,用
表示。智能体在坐标(i, j)处“未来将会获得的数字之和的期望的最大值” 被称为最优策略下的状态-价值函数,用 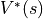 表示。
表示。第三节中,当策略
一定时,智能体在坐标(i, j)处选择动作a时 “现在及未来将会获得的数字之和的期望” 被称为动作-价值函数(Action-Value Function),用 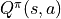 表示。最优策略下的状态-价值函数用
表示。最优策略下的状态-价值函数用 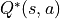 表示。
表示。在第三节和第四节中,使用试验结果直接取均值估计
的方法,称为蒙特卡罗方法。 (7) 中用 来近似替代的 的方法称为时间差分法, (7) 的q值更新方法本身称为SARSA方法。 (8) 称之为Q-learning方法。
推荐阅读
如果读者希望进一步理解强化学习相关知识,可以参考
SJTU Multi-Agent Reinforcement Learning Tutorial (简明的强化学习入门幻灯片)
强化学习知识大讲堂 (内容广泛的中文强化学习专栏)
RLChina强化学习夏令营 (包含前沿内容的强化学习课程,课件及视频可在线观看,亦有微信公众号“RLCN”)
郭宪, 方勇纯. 深入浅出强化学习:原理入门. 电子工业出版社, 2018. (较为通俗易懂的中文强化学习入门教程)
UCL Course on RL (经典的强化学习课程,课件及视频可在线观看)
UC Berkeley CS285: Deep Reinforcement Learning (也是出色的强化学习课程)
Richard S. Sutton, Andrew G. Barto. 强化学习(第二版). 电子工业出版社, 2019. (较为系统的经典强化学习教材,英文原版 可在线阅读 )
- 1
所以有时又被称为“记忆化搜索”,或者说记忆化搜索是动态规划的一种具体实现形式。
- 2
期望是试验中每次可能结果的概率乘以其结果的总和,反映了随机变量平均取值的大小。例如,你在一次投资中有
的概率赚100元,有 的概率赚200元,则你本次投资赚取金额的期望为 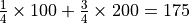 元。也就是说,如果你重复这项投资多次,则所获收益的平均值趋近于175元。
元。也就是说,如果你重复这项投资多次,则所获收益的平均值趋近于175元。- 3
作为参考,在前节中,
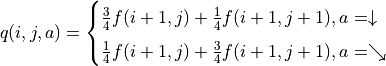
- 4
这里和下文中的“精确”都是相对于迭代算法的有限次试验而言的。只要是基于试验的方法,所获得的期望都是估计值。
- 5
不过在这里,如果我们在迭代第一步的试验时加入了随机扰动的“探索策略”的话,这样计算是不太对的。因为k次试验结果受到了探索策略的影响,导致我们所评估的其实是随机扰动后的动作
,使得我们根据试验结果统计出的 存在偏差。为了解决这个问题,我们有两种方法。第一种方法是把随机扰动的“探索策略”加到第三步策略改进选择最大期望的过程里,第二种则需要采用一种叫做“重要度采样”(Importance Sampling)的方法。由于我们真实采用的q值更新方法多是后面介绍的时间差分方法,所以这里省略关于重要度采样的介绍,有需要的读者可参考文末列出的强化学习相关文献进行了解。